


The State of Engineering Metrics
Part 2. The Practice


My last post covered an overview of the highly dynamic Engineering metrics space. The state of the art has advanced quickly in recent years with new standards emerging and the Software Engineering Intelligence (SEI) product category evolving from nascent to well defined and hotly competitive.
On the one hand, Engineering metrics isn’t a “QED” solved problem. No standard has universal acceptance, and most Engineering leaders I talk to aren’t 100% satisfied with their metrics model. But despite this, the attention being paid to metrics has never been greater, and stakeholder expectations from CEOs and boards of directors have never been higher when it comes to thoughtful metrics related to the success of Engineering org. And SEI platforms have become a standard expectation of the supporting software stack for Engineering organizations.
We can only expect this trend to continue.
It feels like the software industry is experiencing an unprecedented amount of change. The still-recent shift from the “zero interest rate” environment paired with a great deal of forward looking economic uncertainty has created renewed focus on Engineering efficiency and productivity. And the rapid emergence and massive anticipated impact of AI in software engineering is upending how we organize and work. It’s never been more important to have an objective, quantitative view of organizational performance.
So, without a “perfect” – or even easy – answer available off the shelf, Engineering leaders have to be pragmatic and adopt a metrics strategy that makes the best use of the advancing research and product advancements in the space, while also adapting these to the particular needs of their organization. This post looks at ideas for doing just that.
Framing a Strategy
While there’s no “one size fits all” answer to Engineering metrics, there are important and practical actions that can be taken depending on the organization. As a starting point, I’ve found that two main factors inform the highest level inputs into how to proceed: (1) the scale of the organization and (2) complexity of the organization.
Scale
Scale, defined here as the number of Engineers on the team, influences how we approach metrics for pretty clear reasons. On the one hand, scale raises the stakes. At larger scale it’s harder to know anecdotally what’s going on, and therefore much easier for inefficiency and misdirected investment to creep in.
And scale makes objectivity harder. On a small team it’s often possible to maintain a deep enough grasp of the actual work on the ground to assess what’s working well versus what needs improvement. But at larger scale where direct visibility is reduced, it’s harder to discern where work is going well or where communication issues might be hiding both challenges and under-celebrated wins.
Complexity
Organizational complexity matters a lot both in terms of the visibility challenges that it can create, and also as a barrier to improving measurement. By complexity, I mean specifically the degree to which the organization works in a consistent and observable manner – less consistency means more complexity.
If your team is working across various products in a number of SCM systems, using different ticketing platforms (or using tools like ticketing and PRs inconsistently) for whatever historical reasons – it’s simply that much harder to get a comprehensive and consistent view into the work that’s happening. And good luck trying to either overlay an SEI platform or a DIY BI solution on top of a mixed bag of processes and source systems. It’s not just practically harder because of the heterogeneity, but you’re unlikely to get a semantically meaningful view if you do manage to get all of the data in one place.
As an industry, we’ve advanced so much in terms of appreciating observability in our software systems. Observability in our people systems is an equally important unlock.
Depending on where you are in this two dimensional space of scale and complexity, there are meaningful actions to take, as shown in the diagram below:
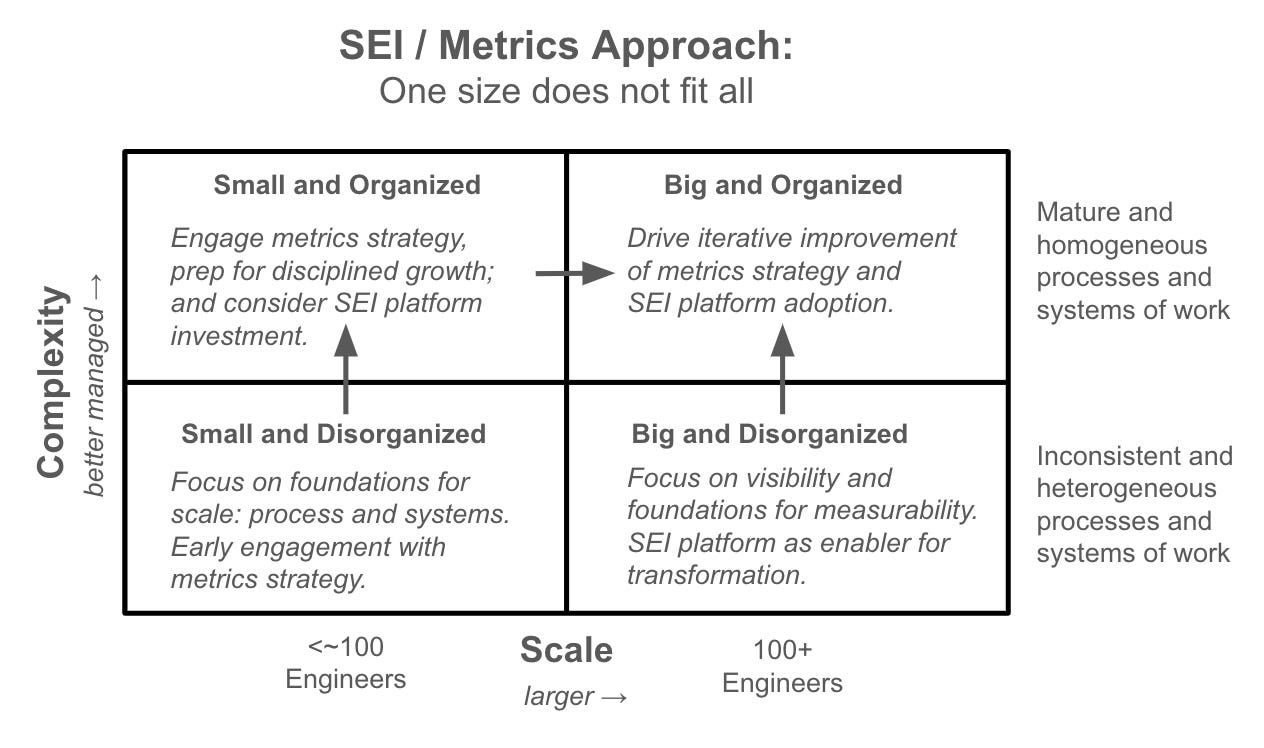
The central approach of this framework is to focus on the long term ability of the organization to implement a strong metrics strategy.
Simplify First
Complexity is probably the first thing to consider. If your systems and processes are messy and/or varied, I would suggest focusing energy into simplifying and cleaning things up so that you have a more observable and measurable environment. This can be challenging in terms of motivating the change management, since metrics are generally not a “quick fix” to any problem, but rather a long term foundation for a healthy and efficient operation. Expect to face questions about the priority of such investments and the real value that they will create.
To mitigate this, I recommend focusing on the essentials. Don’t overdo it. For example, I recently managed an environment with teams running a variety of sprint processes, from Scrum-like iterations to Kanban. Personally, I saw greater value in metrics such as DORA (which has no relationship to sprints), developer experience surveys, and delivery predictability. So I didn’t spend my change management chips on pushing for process consolidation. But this same group was running a variety of ticketing systems when I started, and didn’t have established data hygiene around timely updates to tickets, linking tickets to PRs, etc. Having a clean picture of workflow in a single ticketing system and SCM was directly linked to the types of metrics I found most relevant, so that’s where I put my energy.
Index investment to Scale
Assuming appropriate investment is directed to reducing complexity and increasing measurability, scale answers the question of how much to prioritize investing in metrics. On smaller teams you generally have an accurate picture of how work is flowing without needing a very developed metrics system (although small scale is when the change management to introduce a culture of measurability is easiest). At a larger scale where visibility is inherently harder, having solid metrics reporting capability and also an SEI platform in place, have become fairly “table stakes” expectations.
In recent years, when it comes to Engineering metrics, the industry norm has shifted from DIY to packaged solutions. Packaged products offer a more comprehensive set of measures than you’ll likely implement on your own. And the metrics that these products provide are implemented with solid quality, and often packaged with benchmarks pulled from across many companies for comparison purposes.
Of course, implementing an SEI platform is not only valuable for larger orgs. I’ve run SEI platforms in smaller teams, and they do deliver value. In environments where we likely have a good handle on what’s going on just through solid lines of communication, metrics still help us confirm and quantify our intuitions, not to mention surfacing the occasional surprise that gives us a heads up when things are getting harder to track (e.g., the “Wow, I really didn’t know maintenance on that product was costing that much!” moment). And perhaps more importantly, starting early can set you up to handle the later challenges at scale more easily. It’s easier to gain confidence in the metrics that matter, and also embed them in the culture of the organization, when you’re able to simultaneously validate the value of the metrics by comparing them to your direct experience. Later, when you are “flying by instrument” you’ll have greater conviction that you’re staying on course.
For large organizations, even in higher complexity orgs at scale (for example, orgs that have a variety of tools and processes after being brought together through M&A or reorganizations), getting an SEI platform in place can provide great value even if you’re not able to jump directly to the metrics you’d like to be managing. SEI tools create visibility, which is especially hard in complex environments. You can gain a handle on what types of work are happening in various parts of the org, as well as getting better visibility to process and data challenges. This type of visibility can help you chart a course to process and tooling improvements that will be necessary to transform into a measurable organization.
What to Measure
Of course, the most important question in the metrics strategy is which metrics to focus on. While the answer is dependent on your organization, the good news (or bad news depending on how you look at it) is that there’s never been more information available to build on – from standards, to vendor capabilities, to industry discussion of metrics.
Of course, approaching metrics is rarely a greenfield exercise, and most organizations have a number of metrics in place already, including basic metrics that come from your core systems of work (e.g., Github metrics, Jira reporting, etc.). And whether you’re starting with a lot or a little, it’s always recommendable to work incrementally – focus on a small number of metrics, ensure organizational buy in and adoption, and prove value.
That said, my approach is to consider my primary requirement drivers, and evolve my metrics strategy to ensure that these needs are met. Specifically, as an Engineering leader, the primary requirements for my metrics strategy are:
Ensuring that I can provide a clear picture of Engineering execution to the exec team and board of directors specifically around cost effectively supporting the needs of the business
Ensuring that I have a clear picture of the greatest opportunities for continued improvement of execution, and can measure the impact of investing in these opportunities
Board and Stakeholder Needs
Considering the typical requirements of executive stakeholders and the board of directors, we need metrics that cover at least these bases:
Allocation: What is the actual investment mix between categories of investments (e.g., long term growth, near term growth, customer retention, maintenance, etc.), as well as the allocation across strategic areas such as specific products or strategic projects? This is a top concern for most stakeholders.
Delivery: Of course, we want to know that delivery is on track – not just investment, but actual product out the door. This can include some activity measures such as cycle time, volume of PRs on the team, etc. But most stakeholders also want to understand predictability – is the team hitting commitments? It’s usually also helpful to be able to show key deliverables in flight, as long as the granularity is appropriately consumable (i.e., at the product or feature level, not at the user story level!).
Quality: It’s critical to have reasonable quantitative measures of quality such as escaping defects, number of incidents, time to restore service, time / cost spent on fixing defects, etc. These help clarify whether the organization is on sound footing from a technical debt perspective. And they also provide a critical reality check if customers are frequently raising quality concerns.
People: The talent picture for an Engineering organization is essential to understanding execution capability and potential. It’s important to be able to clearly show people operations such as hiring, onboarding, retention, and team structure.
[NEW] AI Impact: Many of my peers are beginning to add board slides on AI impact.. Expectations from CEOs and boards are all over the map in terms of how much faster AI will let us build software. It’s early in the going here, but given the importance of this question, this is a new area I would include on my metrics roadmap.
These areas cover the basics that most CEOs and boards will want to see from Engineering (and there are some nice resources available that give specific templates to work from to deliver this information, for example Jellyfish has published 5 Slides R&D Leaders Should Show at Board Meetings).
Beyond the core areas covered above, it’s worth noting that stakeholders are becoming more aware of emerging standards like DORA and SPACE. It’s increasingly valuable to be able to report these standard metrics, ideally in the context of the above categories. Beyond the board, if you find yourself representing your Engineering org to potential investors or an M&A acquirer, these days being able to report on DORA metrics (where appropriate, in a services environment) or frame your metrics using a standard such as SPACE, sends a good message about your metrics strategy maturity.
Finally, although it’s beyond the immediate scope of Engineering, it’s important to also ensure that the above Engineering metrics are paired with appropriate Product metrics, especially metrics that look at customer value realization. These can include measures of product adoption – for example basics such as Monthly or Daily Active Users (MAU/DAU) – or usage metrics. For instance, for a business workflow product, a measure such as “count of workflows executed” or “tasks completed” can often serve as a close proxy for customer value. This is of course a whole subject unto itself. The key point here is that Engineering metrics are often most interesting as part of a larger “Product / R&D” treatment, where the goal is a healthy system that creates and maintains products that deliver solid and increasing value to customers (which we then hope a GTM team can monetize very effectively!).
Internal Team Management Needs
Reporting up and out is about providing clarity about how investment is directed, and showing clearly how well execution is working. Of course, the Engineering leader and management team need more from metrics. In particular, they need visibility into problems that hinder execution and specific changes or actions they can take to course correct.
In terms of detecting problems, I’ve always been a huge fan of aligning outbound reporting with internal management metrics as much as possible. This approach maximizes the value of the investment you need to make to ensure data quality and process adherence support your core metrics. Plus it means that the team is paying attention early to the actual results you’ll report later.
While these metrics provide a picture, they of course don't tell you what to do about the issues themselves. For that insight, the best and clearest answer is survey and sentiment data, often called developer experience. Developer experience surveys have been established as an essential practice in modern engineering environments. While the original intent may have been to understand sentiment and engagement, which is absolutely critical, these surveys also provide invaluable insights into the best opportunities for improving the environment. This includes processes, tools, technical investments, quality practices, organizational capabilities, etc. – essentially everything about how the organization works. The people closest to the work are the best at reporting where they’re experiencing friction. And in today’s plugged in world where new ideas and practices are widely shared, the team will often highlight not just the problems, but also some of the best ideas for solutions.
Execution Considerations
"Baseball is 90 percent mental — the other half is physical"
–Yogi Berra
This famous quote from the ever quotable Yogi Berra might equally apply to Engineering metrics, where 90 percent is strategy, but easily another half is execution! Having spent a good part of my career working on data warehousing and analytics products, I’ve found that this is generally true of reporting and metrics. Even if you have the perfect theoretical approach, a huge amount of actual value realization is in getting the organization to deeply engage with the data, and build it into their culture.
Change Management
First, recognize that adopting metrics is a major change for most organizations when they initially take it on, or even when they are stepping up their level of seriousness. It needs to be handled and communicated as a top level organizational priority, and a named initiative. There should be appropriate staffing, such as a working group. There should be a phased project plan, including establishing goals, design, and ongoing governance. Maybe this all sounds heavy handed, but in my experience every organization has many levels of projects or activities that are taken on, ranging from small and informal, to large and formalized. Metrics are hard to get established, and so they are best handled on the larger and more formalized side of the spectrum.
This should include a thoughtful communications plan. For example, make sure that the team is made aware of the goals and the plan at the outset, and then regularly communicate how the program is going. Engineering metrics can have a negative connotation for people on the team – part “Big Brother,” and part over-simplified measurement that doesn’t reflect the reality of building and shipping software. If you don’t combat that perception, how can you expect people to care about the data and process hygiene necessary to power measurability? Transparency and a bit of salesmanship are the best ways to counter this.
Enlisting Champions
One specific tactic around governance and change management is enlisting owners / champions for your metrics practice. In many cases there are natural choices for playing this role, such as a Director of DevEx, a head of Technical Program Management, or an Engineering Ops leader. Whether or not such an “organic” choice exists, it’s still critical to have an engaged leader for the metrics program. Metrics is a long term journey that requires continued evolution and engagement over time, so having a lead in place is essential.
Beyond the lead, it can be valuable to have a working group or guild construct, especially if there are team level Engineering Managers (EMs) willing and interested in participating. Team level managers are often a key ingredient to making a metrics strategy work, since they are on the front line of managing development processes. Yet SEI products and the organizational metrics strategy in many cases don’t quickly and obviously benefit the EM. Having team EMs integrated into the process of connecting the value of the metrics program to team level management will both cause the metrics program to create more value for the organization and ensure that the right care is taken around process and data necessary to correctly power metrics.
Incremental Evolution
Getting metrics really working is hard. The data needs to be in place, which means the underlying processes need to be followed. And then the analytics / SEI infrastructure needs to be established as well. Next, people need to be watching the metrics and taking action - actually managing to the metrics. Reporting on the metrics needs to happen regularly and it needs to matter. If any of these steps fail, the whole value chain can start to erode. The metrics get less accurate. People look at them and care less. And then it falls into disuse.
It may seem hopeless, but it can be solved. The only sane answer I’ve seen really work is to break down the problem. If you try to solve all of it at once, you’re bound to struggle. But what if you could pick one or two metrics and just focus on those? Then you’d have a fighting chance of making it all work. Plus, the organization would gain the confidence to actually take more meaningful steps towards data driven management, such that the next metrics you take on will be that much easier to get established in the organization.
Again, treating metrics as a program, not a point in time project, and certainly not a “set it and forget it” concept, will ensure that you can keep your metrics adoption moving in the right direction.
Avoid Perfectionism
Speaking from personal experience, Engineering metrics design is frustrating. It tends to defy achieving solutions that feel truly satisfying. This “messiness” of the problem creates a hazard for metrics programs, where you can end up in analysis paralysis, bike shedding, etc. It’s best to go in ahead of time knowing that you’re looking to hit a pareto rule of quality, not perfection.
As an illustrative example, it’s often tempting to get concerned about how “general” metrics for the majority of the team will apply to “special” teams. For example, you might have an ML team that works differently from your main feature teams. Or you might have a platform team that mainly services internal technical requirements, not customer roadmap. Or any number of other teams that just don’t fit the standard mold. In these cases, it’s tempting to want to make the metrics work for those teams, either by adapting the metric definition, adapting how the team works, or perhaps both. Going down this road leads to insanity.
My recommendation is to focus on clean definitions (e.g., for ticket classifications, workflow states, etc.), ensure these are applied consistently, and then be smart about interpreting the resulting metrics. It may not make sense to blend your ML team’s PR flow metrics into the top level picture. Or if you have Platform team tickets classified as “roadmap” because they are following an internal roadmap, and find that then your top level investment allocation around customer roadmap looks wrong, consider simplifying. Label platform tickets as “technical investment” and only tag them further as “internal roadmap” if breaking down allocations at that level is really interesting (spoiler, it’s probably not).
Keep it clear and simple, keep it practical, and above all keep the program moving.
Stay the Course
Closely related to incremental evolution, staying the course on metrics is critically important. This means not just sustaining a metrics program and investing over time. But also avoiding churn on the metrics in use. Seeing the same metrics show up meeting after meeting, quarterly board report after quarterly board report, will allow you to create momentum built on the foundation of thoughtfully designed and consistent metrics. Plus staying consistent will give you the actual time to get all of the steps described above right such that you actually get to the point where each metric delivers value!
Of course this isn’t a hard and fast rule – certainly in this fast-moving space, new metrics will emerge as existing metrics fall out of favor. Or changes may happen in your business that require a different focus. But as hard as Engineering metrics are, one of the benefits that we do have is that we tend to work in consistent ways even through business changes, allowing metrics approaches that are durable over time.
Summary
I hope this post gives you a decent picture of the current state of Engineering metrics practices and adoption considerations. My goal was to capture the state of the practice at a high level, but even that is hard to keep to a consumable length. My hope is to return to this topic through a series of posts diving deeper into the areas touched here, and related topics such as implementation considerations.
Until then, thanks for reading and happy metricing!